Data Update 1 for 2024: The Data Speaks, but what is it saying?

In January 1993, I was valuing a retail company, and I found myself wondering what a reasonable margin was for a firm operating in the retail business. In pursuit of an answer to that question, I used company-specific data from Value Line, one of the earliest entrants into the investment data business, to compute an industry average. The numbers that I computed opened my eyes to how much perspective on the high, low, and typical values, i.e., the distribution of margins, helped in valuing the company, and how little information there was available, at least at that time, on this dimension. That year, I computed these industry-level statistics for five variables that I found myself using repeatedly in my valuations, and once I had them, I could not think of a good reason to keep them secret. After all, I had no plans on becoming a data service, and making them available to others cost me absolutely nothing. In fact, that year, my sharing was limited to the students in my classes, but in the years following, as the internet became an integral part of our lives, I extended that sharing to anyone who happened to stumble upon my website. That process has become a start-of-the-year ritual, and as data has become more accessible and my data analysis tools more powerful, those five variables have expanded out to more than two hundred variables, and my reach has extended from the US stocks that Value Line followed to all publicly traded companies across the globe on much more wide-reaching databases. Along the way, more people than I ever imagined have found my data of use, and while I still have no desire to be a data service, I have an obligation to be transparent about my data analysis processes. I have also developed a practice in the last decade of spending much of January exploring what the data tells us, and does not tell us, about the investing, financing and dividend choices that companies made during the most recent year. In this, the first of the data posts for this year, I will describe my data, in terms of geographic spread and industrial breakdown, the variables that I estimate and report on, the choices I make when I analyze data, as well as caveats on best uses and biggest misuses of the data.
The Sample
While there are numerous services, including many free ones, that report data statistics, broken down by geography and industry, many look at only subsamples (companies in the most widely used indices, large market cap companies, only liquid markets), often with sensible rationale – that these companies carry the largest weight in markets or have the most reliable information on them. Early in my estimation life, I decided that while this rationale made sense, the sampling, no matter how well intentioned, created sampling bias. Thus, looking at only the companies in the S&P 500 may give you more reliable data, with fewer missing observations, but your results will reflect what large market cap companies in any sector or industry do, rather than what is typical for that industry.
Since I am lucky enough to have access to databases that carry data on all publicly traded stocks, I choose all publicly traded companies, with a market price that exceeds zero, as my universe, for computing all statistics. In January 2024, that universe had 47,698 companies, spread out across all of the sectors in the numbers and market capitalizations that you see below:
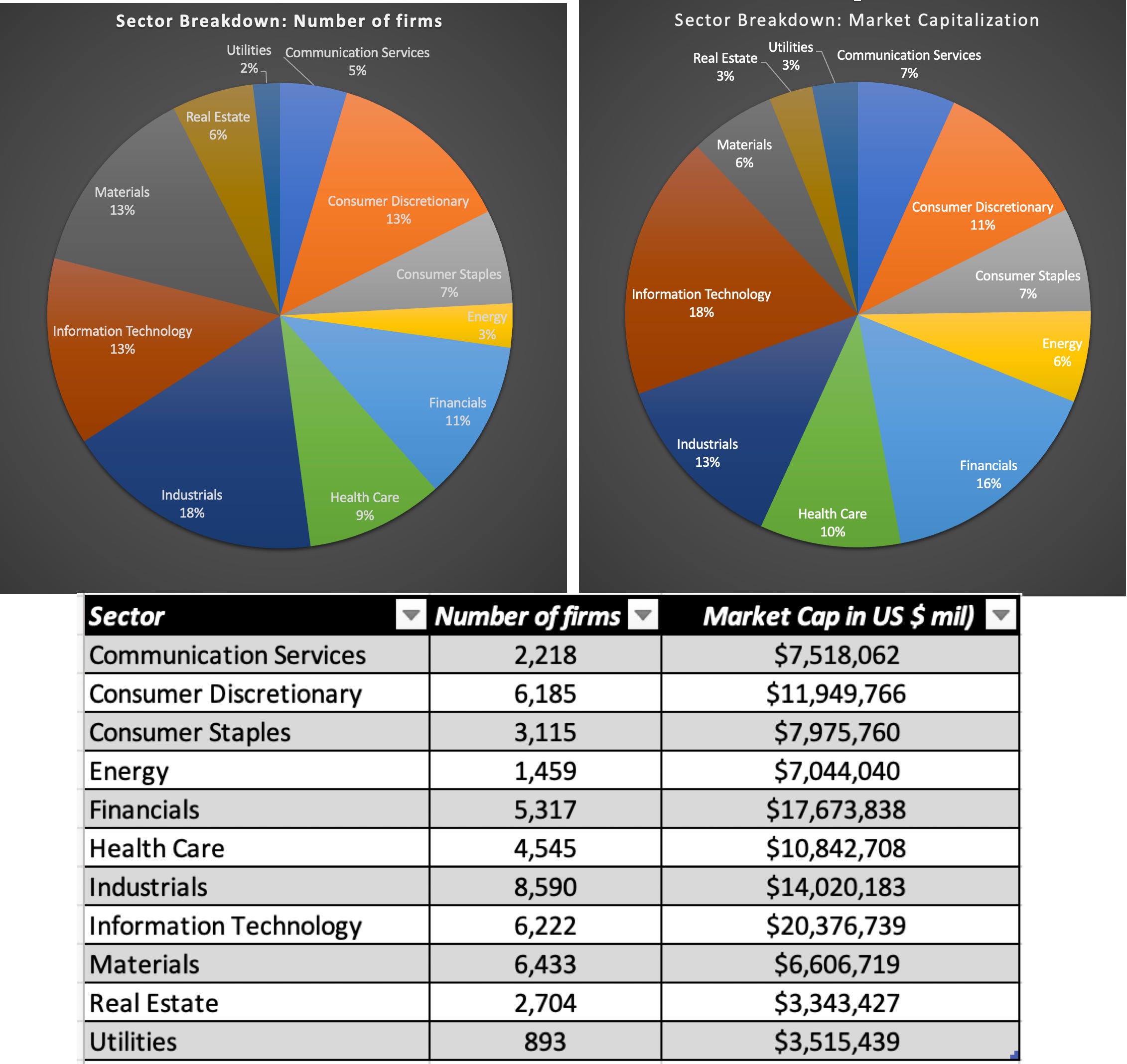
Geographically, these companies are incorporated in 134 countries, and while you can download the number of companies listed, by country, in a dataset at the end of this post, I break the companies down by region into six broad groupings – United States, Europe (including both EU and non-EU countries, but with a few East European countries excluded), Asia excluding Japan, Japan, Australia & Canada (as a combined group) and Emerging Markets (which include all countries not in the other groupings), and the pie chart below provides a picture of the number of firms and market capitalizations of each grouping:
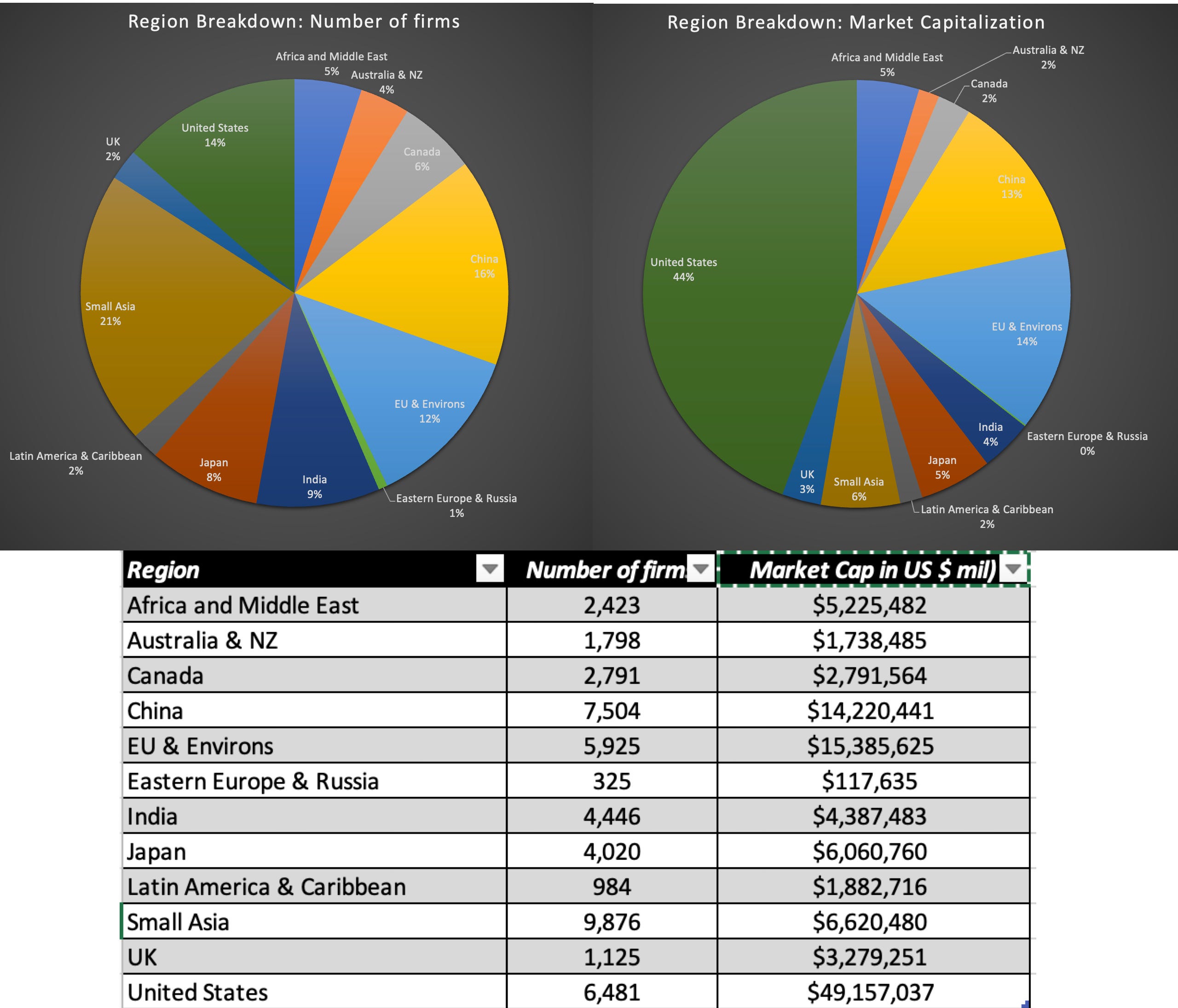
Before you take issue with my categorization, and I am sure that there are countries or at least one country (your own) that I have miscategorized, I have three points to make, representing a combination of mea culpas and explanations. First, these categorizations were created close to twenty years ago, when I first started looking a global data, and many countries that were emerging markets then have developed into more mature markets now. Thus, while much of Eastern Europe was in the emerging market grouping when I started, I have moved those countries that have either adopted the Euro or grown their economies strongly into the Europe grouping. Second, I use these groupings to compute industry averages, by grouping, as well as global averages, and nothing stops you from using the average of a different grouping in your valuation. Thus, if you are from Malaysia, and you believe strongly that Malaysia is more developed than emerging market, you should look at the global averages, instead of the emerging market average. Third, the emerging market grouping is now a large and unwieldy one, including most of Asia (other than Japan), Africa, the Middle East, portions of Eastern Europe and Russia and Latin America. Consequently, I do report industry averages for the two fastest growing emerging markets in India and China.
The Variables
As I mentioned at the start of this post, this entire exercise of collecting and analyzing data is a selfish one, insofar as I compute the data variables that I find useful when doing corporate financial analysis, valuation, or investment analysis. I also have quirks in how I compute widely used statistics like accounting returns on capital or debt ratios, and I will stay with those quirks, no matter what the accounting rule writers say. Thus, I have treated leases as debt in computing debt ratios all through the decades that I have been computing this statistic, even though accounting rules did not do so until 2019, and capitalized R&D, even though accounting has not made that judgment yet.
In my corporate finance class, I describe all decisions that companies make as falling into one of three buckets – investing decisions, financing decision and dividend decisions. My data breakdown reflects this structure, and here are some of the key variables that I compute industry averages for on my site:
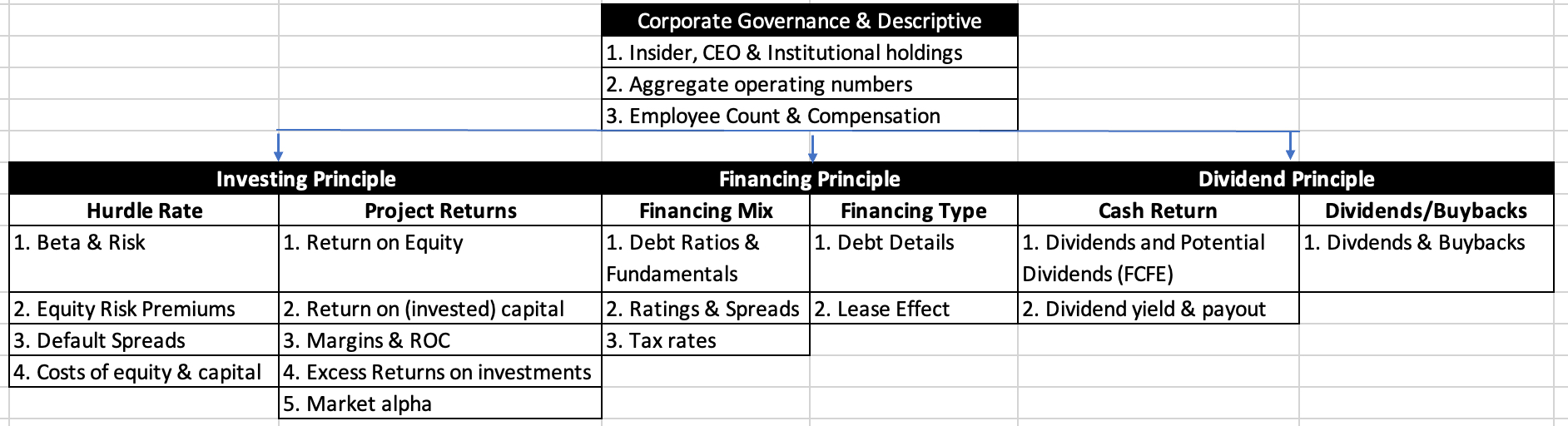
Many of these corporate finance variables, such as the costs of equity and capital, debt ratios and accounting returns also find their way into my valuations, but I add a few variables that are more attuned to my valuation and pricing data needs as well.
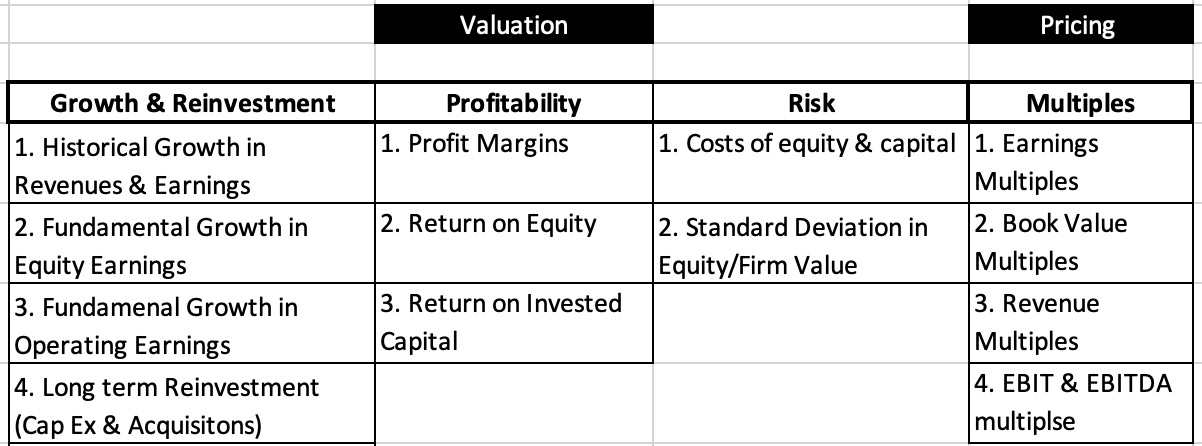
Thus, I compute pricing multiples based on revenues (EV to Sales, Price to Sales), earnings (PE, PEG), book value (PBV, EV to Invested Capital) or cash flow proxies (EV to EBITDA). In recent years, I have also added employee statistics (number of employees and stock-based compensation) and measures of goodwill (not because it provides valuable information but because of its potential to cause damage to your analysis).
My data is primarily micro-focused, since there are other services that are much better positioned to provide macro data (on inflation, interest rates, exchange rates etc.). My favorite remains the Federal Reserve data site in St. Louis (know as FRED, and one of the great free data resources in the world), but there are a few macro data items that I estimate, primarily because they are not as easily available, or if available, are exposed to estimation choices. Thus, I report annual historical returns on asset classes (stocks, bonds, real estate, gold) going back to 1928, mostly because data services seem to focus on individual asset classes and partly because I want to make sure that returns are computed the way I want them to be. I also have implied equity risk premiums (forward-looking and dynamic estimate of what investors are pricing stocks to earn in the future) for the S&P 500 going back annually to 1960 and monthly to 2008, and equity risk premiums for countries.
The Industry Groupings
I am aware that there are industry groupings that are widely used, including industry codes (SIC and NAICS), I have steered away from these in creating my industry groupings for a few reasons. First, I wanted to create industry groupings that were intuitive to use for analysts looking for peer groups, when analyzing companies. Second, I wanted to maintain a balance in the number of groupings - having too few will make it difficult to differentiate across businesses and having too many will create groupings with too few firms for some parts of the world. The sweet spot, as I see it, is around a hundred industry groupings, and I get pretty close with 95 industry groupings; the table below lists the number of firms within each in my data:
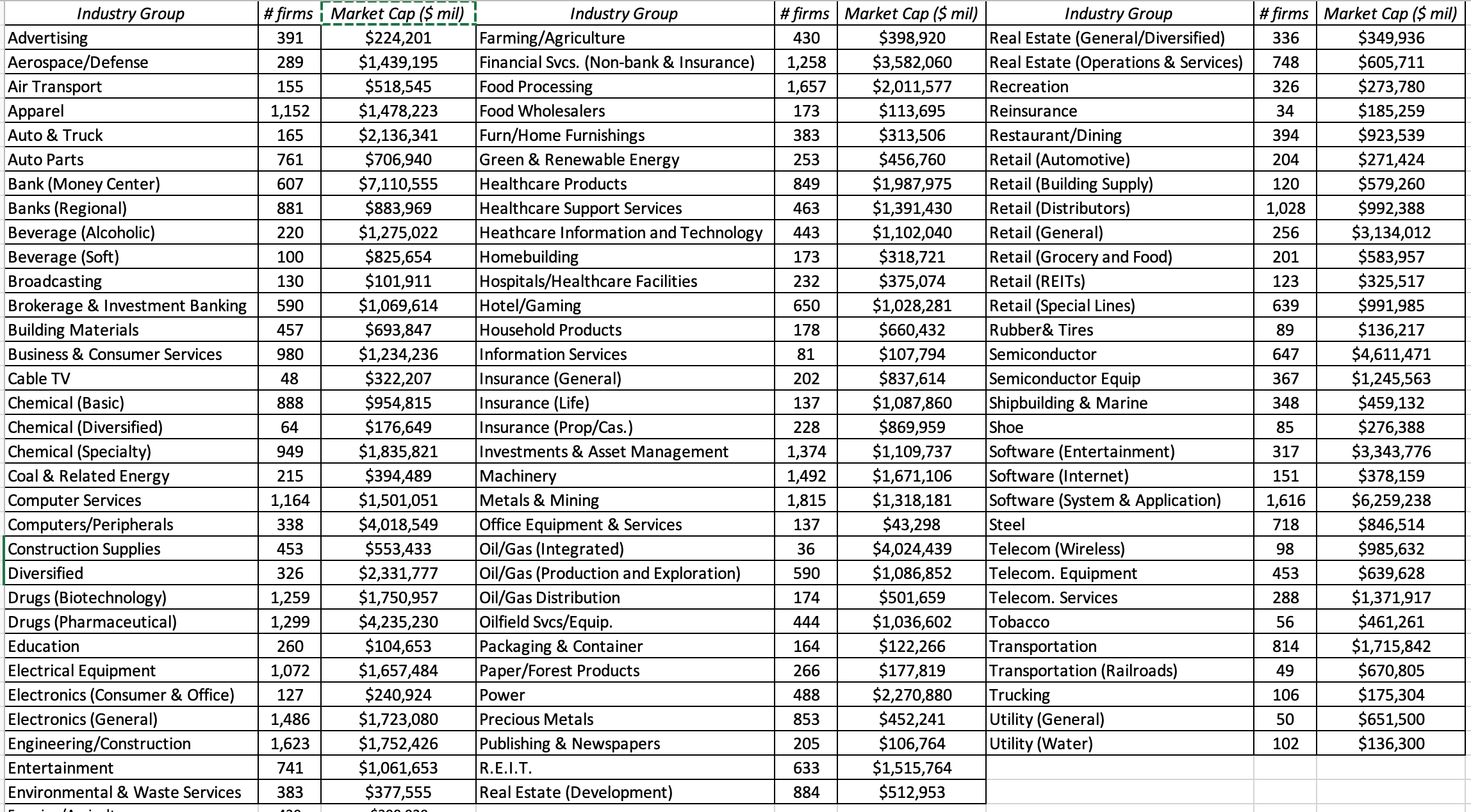
No matter how carefully you create these groupings, you will still face questions about where individual companies fall, especially when each company can be assigned to one industry group. Is Apple a personal computer company, an entertainment company or wireless telecom company? While you can allow it to be in all three, when analyzing the companies, for purposes of computing industry averages, I had to assign each company to a single grouping. If you are interested in seeing which companies fall within each group, you can find it by clicking on this link. (Be patient. This is a large dataset and can take a while to download)
Data Timing & Currency Effects
In computing the statistics for each of the variables, I have one overriding objective, which is to make sure that they reflect the most updated data that I have at the time that I compute them, which is usually the first week of January. That does lead to what some of you may view as timing contradictions, since any statistic based upon market data (costs of equity and capital, equity risk premiums, risk free rates) is updated to the date that I do the analysis (usually the values at the close of the last trading day of the prior year – Dec 31, 2023, for 2024 numbers), but any statistic that uses accounting numbers (revenues, earnings etc.) will reflect the most recent quarterly accounting filing. Thus, when computing my accounting return on equity in January 2024, I will be dividing the earnings from the four quarters ending in September 2023 (trailing twelve month) by the book value of equity at the end of September 2022. Since this is reflecting of what investors in the market have access to at the start of 2024, it fulfils my objective of being the most updated data, notwithstanding the timing mismatch.
There are two perils with computing statistics across companies in different markets. The first is differences in accounting standards, and there is little that I can do about that other than point out that these differences have narrowed over time. The other is the presence of multiple currencies, with companies in different countries reporting their financials in different currencies. The global database that I use for my raw data, S&P Capital IQ, gives me the option of getting all of the data in US dollars, and that allows for aggregation across global companies. In addition, most of the statistics I report are ratios rather than absolute values, and are thus amenable to averaging across multiple countries.
Statistical Choices
In the interests of transparency, it is worth noting that there are data items where the reporting standards either don’t require disclosure in some parts of the world (stock-based compensation) or disclosure is voluntary (employee numbers). When confronted with missing data, I do not throw the entire company out of my sample, but I report the statistics only across companies that report that data.
In all the years that I have computed industry statistics, I have struggled with how best to estimate a number that is representative of the industry. As you will see, when we take a closer look at individual data items in later posts, the simple average, which is the workhorse statistic that most services report for variables, is often a poor measure of what is typical in an industry, either because the variable cannot be computed for many of the companies in the industry, or because, even when computed, it can take on outlier values. Consider the PE ratio, for example, and assume that you trying to measure a representative PE ratio for software companies. If you follow the averaging path, you will compute the PE ratio for each software company and then take a simple average. In doing so, you will run into two problems.
First, when earnings are negative, the PE ratio is not meaningful, and if that happens for a large number of firms in your industry group, the average you estimate is biased, because it is only for the subset of money-making companies in the industry.
Second, since PE ratios cannot be lower than zero but are unconstrained on the upside, you will find the average that you compute to be skewed upwards by the outliers.
Having toyed with alternative approaches, the one that I find offers the best balance is the aggregated ratio. In short, to compute the PE ratio for software companies, I add up the market capitalization of all software companies, including money-losers, and divide by the aggregated earnings across these companies, against including losses. The resulting value uses all of the companies in the sample, reducing sampling bias, and is closer to a weighted average, alleviating the outlier effect. For a few variables, I do report the conventional average and median, just for comparison.
Using the data
As I noted earlier, the datasets that I report are designed for my use, in corporate financial analysis and valuation that I do in real time. Thus, I plan to use the 2024 data that you see, when I value companies or do corporate financial analysis during the year, and if you are a practitioner doing something similar, it should work for you. You can find this current data at this link, organized to reflect the categories.
That said, there are some of you who are not doing your analysis in real time, either because you are in the appraisal business and must value your company as of the start of 2020 or 2021, or a researcher looking at changes over time. I do maintain the archived versions of my datasets for prior years on my webpage, and if you click on the relevant data, you can get the throwback data from prior years.
There are two uses that my data is put to where you are on your own. The first is in legal disputes, where one or both sides of the dispute seem to latch on to data on my site to make their (opposing) cases. While I clearly cannot stop that from happening, please keep me out of those fights, since there is a reason I don’t do expert witness of legal appraisal work; courts are the graveyards for good sense in valuation. The other is in advocacy work, where data from my site is often selectively used to advance a political or business argument. My dataset on what companies pay as tax rates seems to be a favored destination, and I have seen statistics from it used to advance arguments that US companies pay too much or too little in taxes.
Finally, my datasets do not carry company-specific data, since my raw data providers (fairly) constrain me from sharing that data. Thus, if you want to find the cost of capital for Unilever or a return on capital for Apple, you will not find it on my site, but that data is available online already, or can be computed from the financial releases from these companies.
A Sharing Request
I will end this post with words that I have used before in these introductory data posts. If you do use the data, you don’t have to thank me, or even acknowledge my contribution. Use it sensibly, take ownership of your analysis (don’t blame my data for your value being too high or low) and pass on knowledge. It is one of the few things that you can share freely and become richer as you share more. Also, as with any large data exercise, I am sure that there are mistakes that have found their way into the data, and if you find them, let me know, and I will fix them as quickly as I can!
YouTube Video
Sample Breakdown
Links to my data
Data Update Posts for 2024
Data Update 1 for 2024: The data speaks, but what does it say?
Thank you for the effort and time you expend for all of this!!! It would help the uninitiated if you mentioned how the figures are represented (notation) for e.g. the market cap is presented in $ millions.